· INSAIT · Release · 9 min read
Announcing BgGPT 3.0: State-of-the-Art Multimodal LLMs for Bulgarian
We release BgGPT 3.0 — three new open models (4B, 12B, 27B) based on Gemma 3, featuring vision-language understanding, 131k+ context, and significantly improved instruction-following for Bulgarian and English.
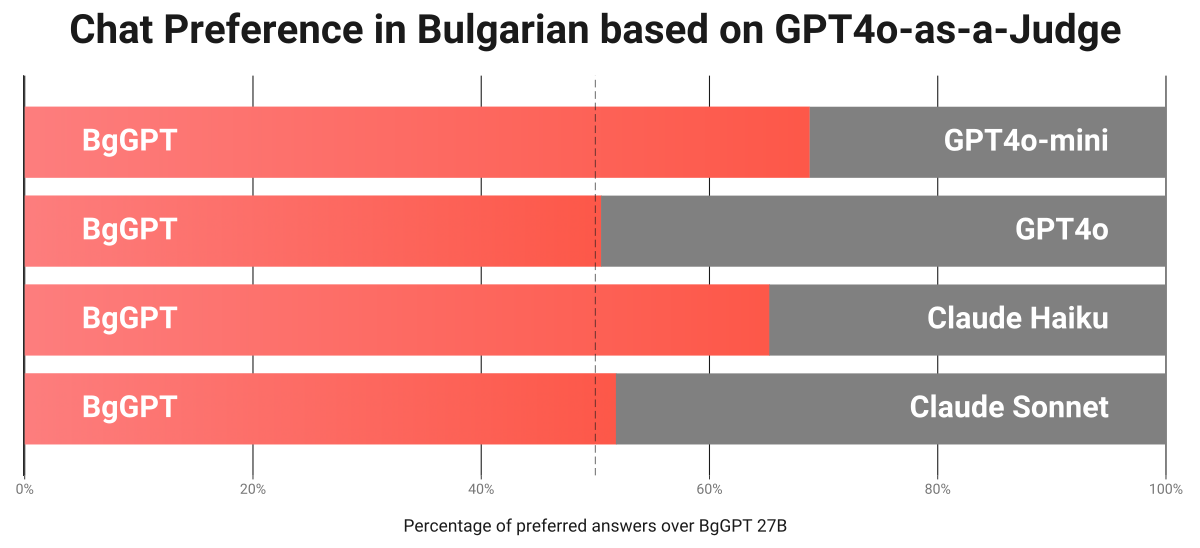
We are delighted to announce the release of BgGPT 3.0, a new state-of-the-art LLM series with a permissive license targeting the Bulgarian language. We are releasing three model sizes — 4B, 12B and 27B — which are cost-efficient, fast and multimodal, yet perform competitively in both Bulgarian and English. The models come with strong base and instruction-following capabilities outpacing open-weight models of much larger sizes.
In the third iteration of our Bulgarian-adapted models, we use Gemma 3 as a robust multilingual base for continual pretraining and supervised fine-tuning. With a stronger base model and further adjustments to the training pipeline, this new version features the following improvements:
Vision-language understanding: The models are designed to understand both text and images within the same context, and we aim to preserve and improve this capability, originally present in the Gemma 3 models.
Instruction-following: In this iteration, we take special care to train the model on a broader range of tasks, multi-turn conversations, more complex instructions, as well as system prompts, resulting in significantly better instruction-following and downstream utility compared to BgGPT version 2.0.
Longer context: With an effective context of 131k tokens, enabled both by the architecture and base training of the Gemma 3 model family, as well as careful adaptation on our side, BgGPT 3.0 now supports longer conversations, long-document understanding and can follow longer and more complex instructions.
Updated knowledge cut-off: In the pretraining phase, we include additional web-crawled documents, as recent as May 2025, while the instruction fine-tuning phase contains knowledge up to October 2025.
Improved Continual Pretraining
Language transfer, similarly to other cases of domain adaptation, poses a multitude of challenges both on the data and training side of the pipeline, some of which, such as catastrophic forgetting, we have addressed in previous releases and research — MamayLM, BgGPT, Alexandrov et al [1]. With a stronger multimodal base model like Gemma 3, the preservation of the original capabilities, i.e., mitigating catastrophic forgetting, is more important than ever. To realize improvements across different modalities, languages, and domains, we conduct a few crucial adjustments to our previous pipeline (BgGPT 2.0).
Web Data Curation
Previously, we relied on an adjusted RedPajama v2 pipeline [2], which helped us gather and curate a set of web documents with creation dates no later than October 2023. This time around, we make a few improvements in the following aspects:
Extraction. We update the set of available documents by reparsing the older ones and extracting the newest Bulgarian ones from CommonCrawl, with a cut-off date of May 2025.
Deduplication. We further apply, in turn, our new exact and fuzzy deduplication pipelines. From 113M unique documents, we remove 78M through fuzzy deduplication, leaving us with a preliminary set of 35M documents.
Filtering. We explore a range of metrics based on document statistics, similar to those used by RedPajama, RefinedWeb, and others. One of the more significant improvements in this area is the really strong annotation signals we obtain from the JQL annotations based on Snowflake embeddings [3].
Rehydration. After filtering, we end up with ~23M documents, which corresponds to less than 40B tokens. In previous versions of BgGPT, we aimed for 100B total tokens in the continual pretraining dataset, but we observed that the quantifiable improvements on benchmarks slowed asymptotically. Inspired by Muenninghoff et al., Fang et al., and FineWeb2 [4][5][6], we perform a rehydration step in which we intentionally repeat documents based on their quality.
Sequence Construction
Modern LLMs, such as Gemma 3, typically undergo a final long-context pretraining stage where they are specifically trained with longer sequences (e.g., 32K tokens for Gemma 3) and RoPE scaling. To this end, during the continual pretraining phase of our pipeline, we carefully construct our training sequences to preserve long-context capabilities while mitigating cross-document interference and catastrophic forgetting. We apply several techniques for this, outlined below.
Document Clustering. We cluster the documents based on 320 centroids through their Snowflake embeddings. This allows us to construct multi-document sequences that only include documents from the same cluster. This reduces hallucinations in real-world use, while closing the domain gap and reinforcing long-context learning.
Best-fit Sequence Packing. Within each cluster, we apply the highly efficient Best-fit packing algorithm from Dint et al. [7] to generate our token sequences, avoiding document splitting while adding fewer than 1% padding tokens.
Model Alignment
The most data-starved stage of model development is supervised instruction fine-tuning and alignment. There is a general lack of Bulgarian QA pairs, as well as Bulgarian conversations and preference data. To address this gap, we use a range of data-sourcing techniques, including translation, synthetic data generation, and human annotation. Finally, model merging delivers strong performance on Bulgarian benchmarks, improves alignment and generalization, and mitigates catastrophic forgetting.
SFT Data Sourcing
In previous versions of BgGPT, we relied primarily on machine-translated open datasets such as Hermes, SlimOrca, and Capybara. With the increased capabilities of SOTA models and the broad public adoption of previous versions of BgGPT, our dataset has expanded to include a blend of synthetic, translated, and real-world data, enabling the model’s better instruction-following capabilities.
To facilitate crosslingual transfer, we continue to anchor our training to high-quality translated English data, containing Math, Code, and Function-calling examples, drawn from sources like WildChat, Olmo-2, and Hermes 3. Additionally, we leverage native Bulgarian instruction-following data originating from the millions of opt-in user queries, collected by our BgGPT chat application. We process these through a rigorous filtering and synthetic data generation pipeline to arrive at a large-scale dataset of user conversations, containing a diverse set of topics, user intents, and quality of language. Finally, we leverage instruction backtranslation [16] to generate synthetic system prompts for some of these conversations.
Branch-and-merge
As with our prior BgGPT models, we leverage our efficient model merging method, featured in this Google DeepMind blog post, to boost the alignment of our model. To this end, we leverage both Gemma 3’s strong base and aligned models, as well as our own fine-tuned models.
Before merging, our fine-tuned models show limited improvements over the original Gemma 3 models. When we start merging them, however, we see that the resulting models perform significantly better than the individual ones that compose the merge. The merging technique we have found to be the most robust and efficient is Spherical Linear Interpolation (SLERP).
Experimental Results
We extend our original benchmark set, discussed in BgGPT 1.0 [8], with IFEval [9], BBH (BigBenchHard) [10], LongBench [11], MMMU [12], and EXAMS-V [13] to address the need to measure instruction-following, reasoning, long-context, and vision-text capabilities. IFEval and BBH required significant effort beyond machine translation to adapt to Bulgarian, while we utilized Universal self-improvement [14] to translate LongBench. You can find the Bulgarian-adapted versions of these benchmarks on our HuggingFace organization page.
In our evaluations, outside of prior versions of BgGPT, we also compare to the Gemma 3 family of models, as they exhibit the strongest multilingual capabilities for both their size and, more generally. We also compare BgGPT to the Qwen family of models, also built with multilinguality in mind, but exhibit a more East Asian skew. We compare to 2 models from the Qwen 3 series [15] that are in a similar inference speed range, namely the 32B dense model and 235B-Instruct MoE, with the latter, of course, requiring several times more memory to serve.
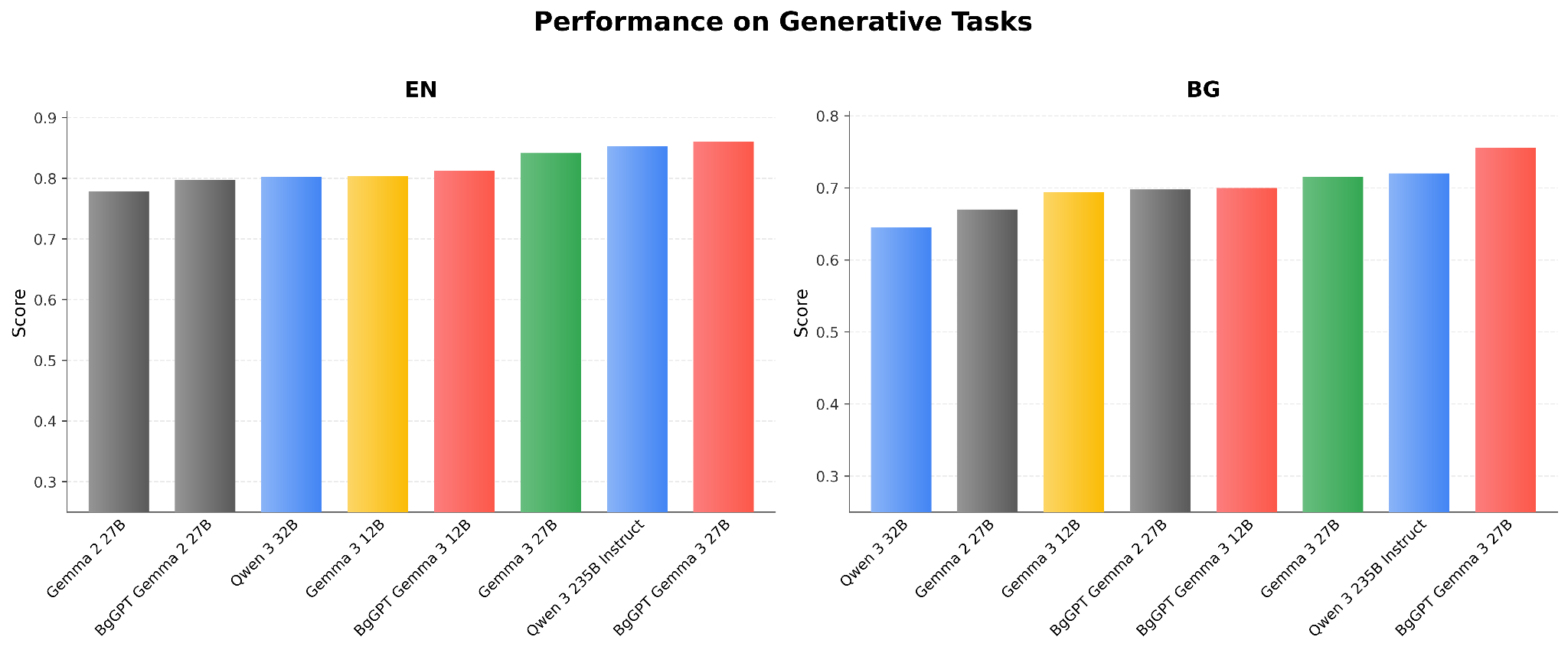
Generative Tasks
Excluding LongBench, our generative benchmark set consists of TriviaQA, GSM8k, IFEval, and BigBenchHard. Figure 1 presents the aggregated scores from these 4 benchmarks for the various models. We can see that BgGPT Gemma 3 27B outpaces all Gemma and both Qwen 3 models in Bulgarian and English. It is important to note that this aggregation obscures certain strengths and weaknesses across the models. For example, comparing Google’s original Gemma 3 12B to our previous BgGPT Gemma 2 27B, despite their similar aggregated Bulgarian scores, we observe 15% lower scores in TriviaQA, stemming from our previous model’s Bulgarian-specific knowledge, but 9% higher scores in IFEval, demonstrating the improved instruction-following capabilities of the 3rd-generation Gemma models. BgGPT Gemma 3 27B combines the strengths of both models, achieving 14% higher scores on IFEval, compared to BgGPT Gemma 2 27B, while retaining the gains on TriviaQA.
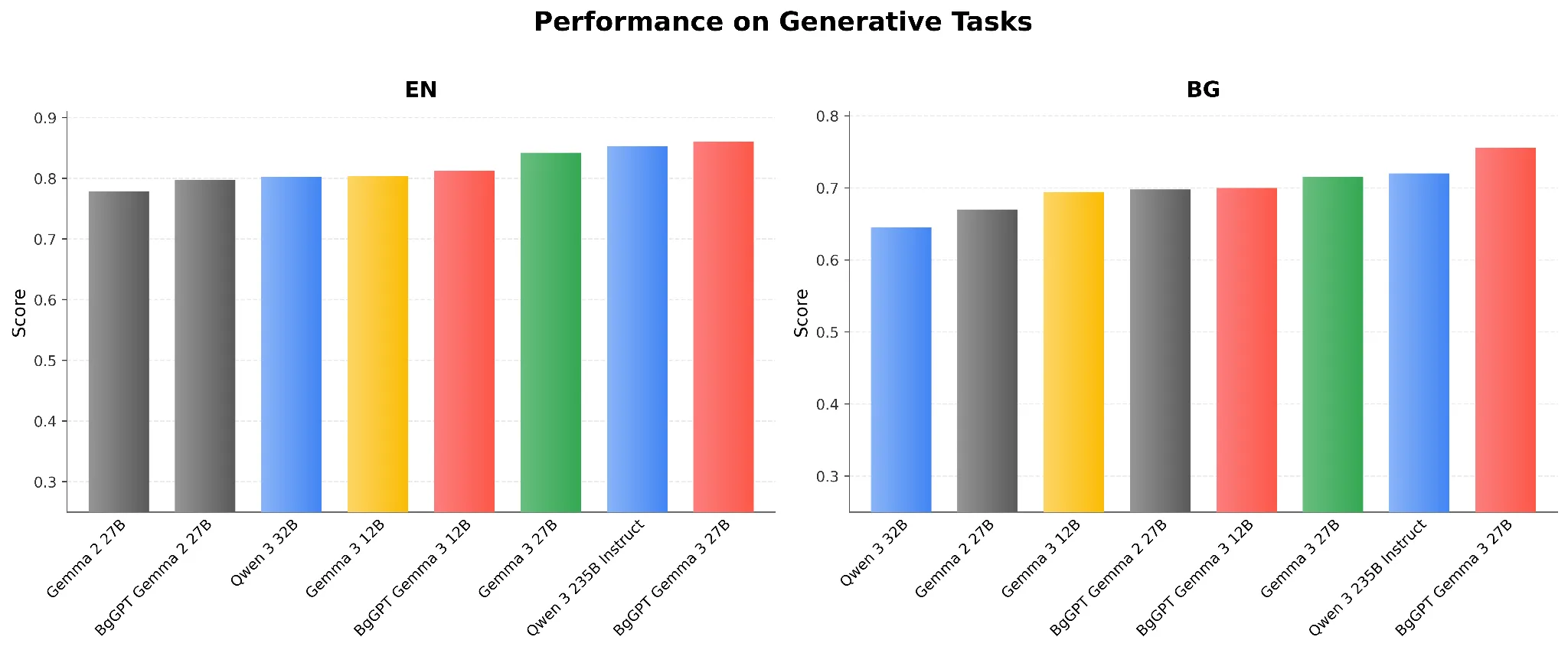
Figure 1: Performance on Generative Tasks
Long-context Tasks
We see that for the original English LongBench, the performance differences between models are moderate, whereas for Bulgarian, greater variance is apparent in Figure 2. The improvements of BgGPT over the same-sized Gemma 3 models are consistent and significant for the Bulgarian language, and the 27B BgGPT model also outperforms even a much larger Qwen 3 235B model.
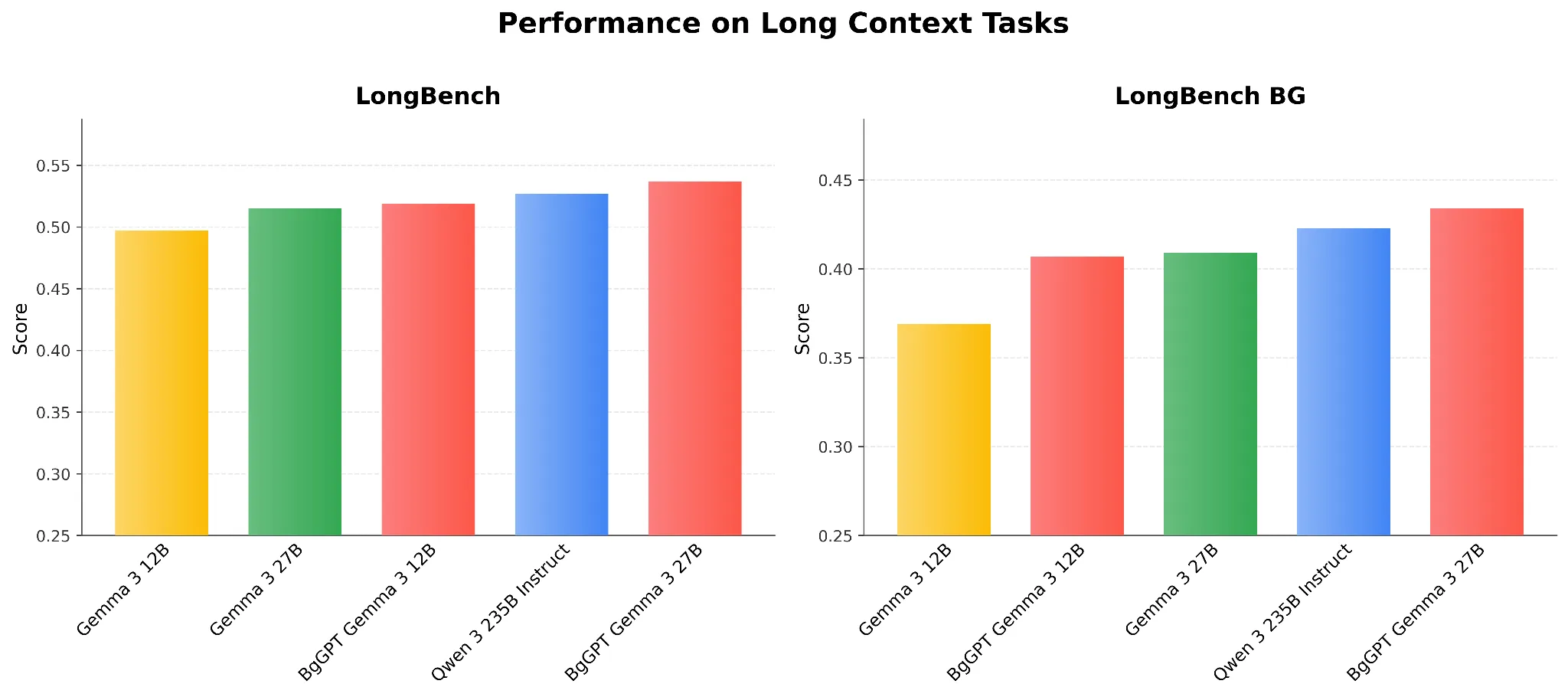
Figure 2: Performance on Long Context Tasks
Image and Text Tasks
In Figure 3, we observe that the BgGPT models of both sizes improve on the English (MMMU) and Bulgarian (EXAMS-V) image-text benchmarks compared with the unaltered Gemma 3 instruction model equivalents. These performance gains are achieved for free: we perform no multimodal training, only appending the original vision tower to the adapted language models. The results are surprising, given that EXAMS-V is a multiple-choice benchmark that contains no text in the queries, which can challenge the assumption that the improvement stems solely from increased language understanding capabilities.
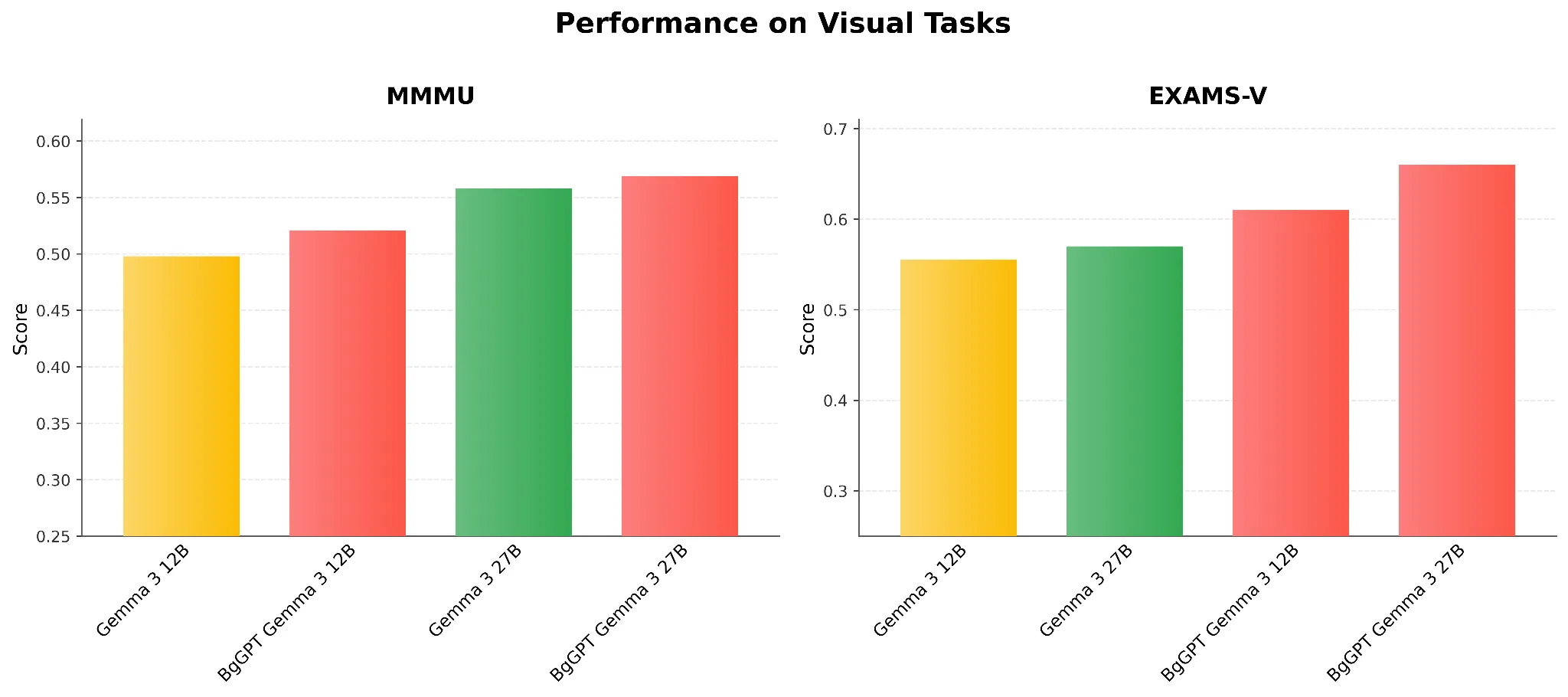
Figure 3: Performance on Visual Tasks
Base Model Performance
Finally, we showcase the capabilities of BgGPT Gemma 3 as a base model, even though it is heavily instruction-tuned, with superior performance on log-probability benchmarks.
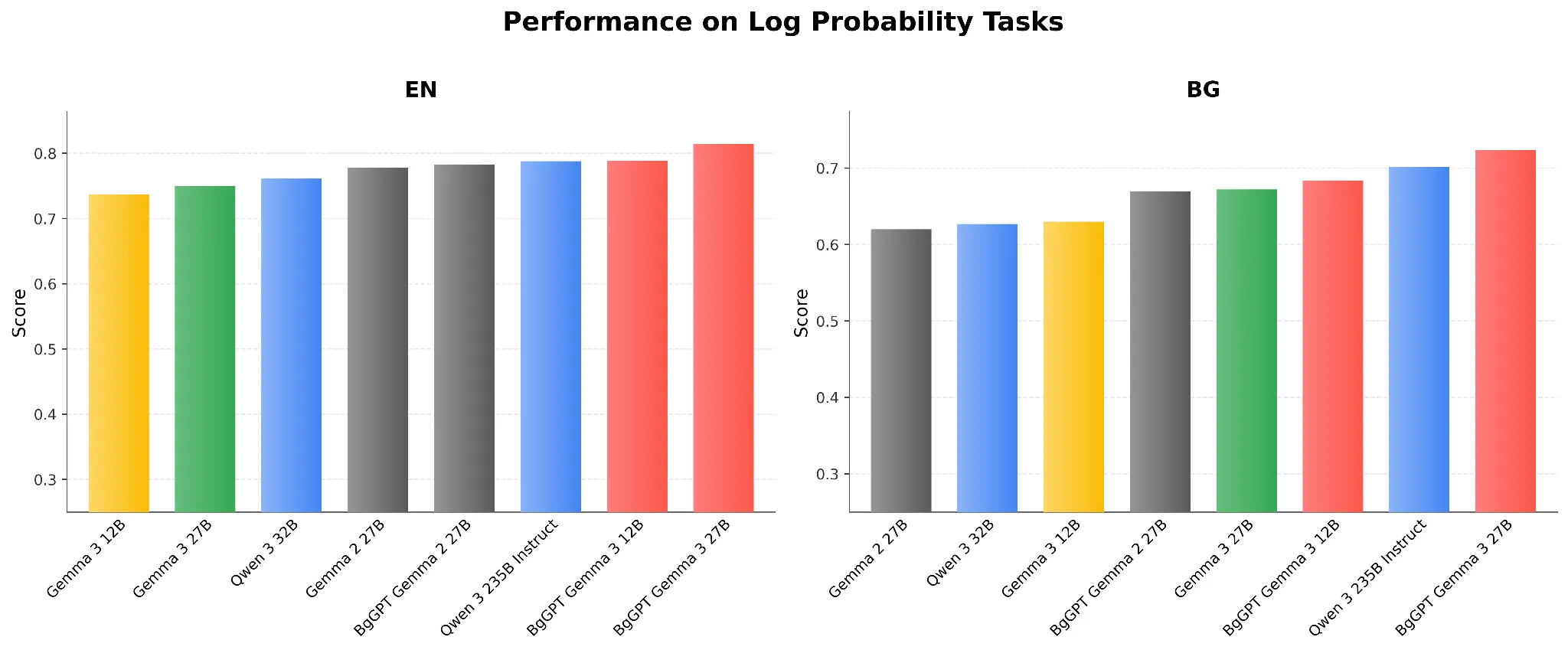
Figure 4: Performance on Log Probability Tasks
INSAIT thanks Google for its continued support, both in terms of GCP credits needed to train the BgGPT models, as well as donations needed for work beyond training.
References
- Mitigating Catastrophic Forgetting in Language Transfer via Model Merging. Findings of EMNLP, 2024. https://aclanthology.org/2024.findings-emnlp.1000/
- RedPajama: an Open Dataset for Training Large Language Models. NeurIPS Datasets & Benchmarks, 2024.
- Judging Quality Across Languages: A Multilingual Approach to Pretraining Data Filtering with Language Models. EMNLP, 2025. https://aclanthology.org/2025.emnlp-main.449
- Scaling Data-Constrained Language Models. arXiv, 2023. https://arxiv.org/abs/2305.16264
- Datasets, Documents, and Repetitions: The Practicalities of Unequal Data Quality. ACL, 2022. https://arxiv.org/abs/2107.06499
- FineWeb2: One Pipeline to Scale Them All — Adapting Pre-Training Data Processing to Every Language. arXiv, 2025. https://arxiv.org/abs/2506.20920
- Fewer Truncations Improve Language Modeling. ICML 2024. https://arxiv.org/abs/2404.10830
- BgGPT 1.0: Extending English-centric LLMs to other languages. arXiv, 2024. https://arxiv.org/abs/2412.10893
- Instruction-Following Evaluation for Large Language Models. ICLR, 2024. https://arxiv.org/abs/2311.07911
- Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them. Findings of ACL, 2022. https://aclanthology.org/2023.findings-acl.824
- LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. ACL, 2024. https://aclanthology.org/2024.acl-long.172/
- MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI. CVPR, 2024.
- EXAMS-V: A Multi-Discipline Multilingual Multimodal Exam Benchmark for Evaluating Vision Language Models. arXiv, 2024. https://arxiv.org/abs/2403.10378
- Recovered in Translation: Efficient Pipeline for Automated Translation of Benchmarks and Datasets. arXiv, 2026. https://arxiv.org/pdf/2602.22207
- Qwen3 Technical Report. arXiv, 2025. https://arxiv.org/abs/2505.09388
- Self-Alignment with Instruction Backtranslation. arXiv, 2023. https://arxiv.org/abs/2308.06259