· INSAIT · Release · 4 min read
INSAIT Releases State-of-the-Art Language Models for Bulgarian Setting a New Standard for Open National LLMs
INSAIT releases three new BgGPT models (27B, 9B, 2.6B) based on Gemma 2, outperforming much larger open models in Bulgarian while rivaling GPT-4o in chat performance.
This is the first time open LLMs of practical size for a target language surpass in performance much larger open models while being competitive for chatting with paid platforms such as OpenAI and Anthropic.
INSAIT is delighted to announce the release of three new state-of-the-art AI models, a 27 billion, a 9 billion, and a small 2.6 billion parameter models, targeting the Bulgarian language (called BgGPT). The 27B and 9B models demonstrate unprecedented performance in Bulgarian, outpacing much larger ones, while retaining English language capabilities. Beyond benchmarks, INSAIT’s 27B model significantly surpasses GPT-4o-mini and rivals GPT-4o in Bulgarian chat performance, according to GPT-4o itself used as a judge. We observe similar results with Anthropic’s Claude Haiku and Sonnet paid models.
INSAIT’s three new models are built on top of Google’s Gemma 2 family of open models and were pre-trained on around 100 billion tokens (85 billion in Bulgarian) using the Branch-and-Merge continual pre-training strategy that INSAIT invented and presented at EMNLP’24 [1]. Further, the models were instruction-fine-tuned on a novel Bulgarian instruction dataset created using real-world conversations collected from https://chat.bggpt.ai/.
New Research: Avoiding Catastrophic Forgetting via Branch-and-Merge

The key to the performance of the new line of BgGPT models is a novel branch and merge algorithm we presented at EMNLP’24 [1]. This method ensures the model can learn new skills (e.g., Bulgarian) while retaining old ones (e.g., English, mathematics, few-shot capabilities) in the base model (e.g., Gemma-2 in this case).
At a high level, the method works by splitting the continuous pre-training datasets into several splits, training a model on each split, and then merging the resulting models, thus mitigating the forgetting associated with the different split models. Generally, the BgGPT models are developed as a series of model merges. We remark that our methodology is general and can be applied beyond Bulgarian as shown in the paper [1].
Benchmarks
We evaluate on a set of standard English benchmarks, a translated version of them in Bulgarian, as well as, Bulgarian specific benchmarks we collected:
- Winogrande challenge [2]: testing world knowledge and understanding
- Hellaswag [3]: testing sentence completion
- ARC Easy/Challenge [4]: testing logical reasoning
- TriviaQA [5]: testing trivia knowledge
- GSM-8K [6]: solving multiple-choice questions in high-school mathematics
- Exams [7]: solving high school problems from natural and social sciences
- MON: contains exams across various subjects for grades 4 to 12
These benchmarks test logical reasoning, mathematics, knowledge, language understanding and other skills of the models.
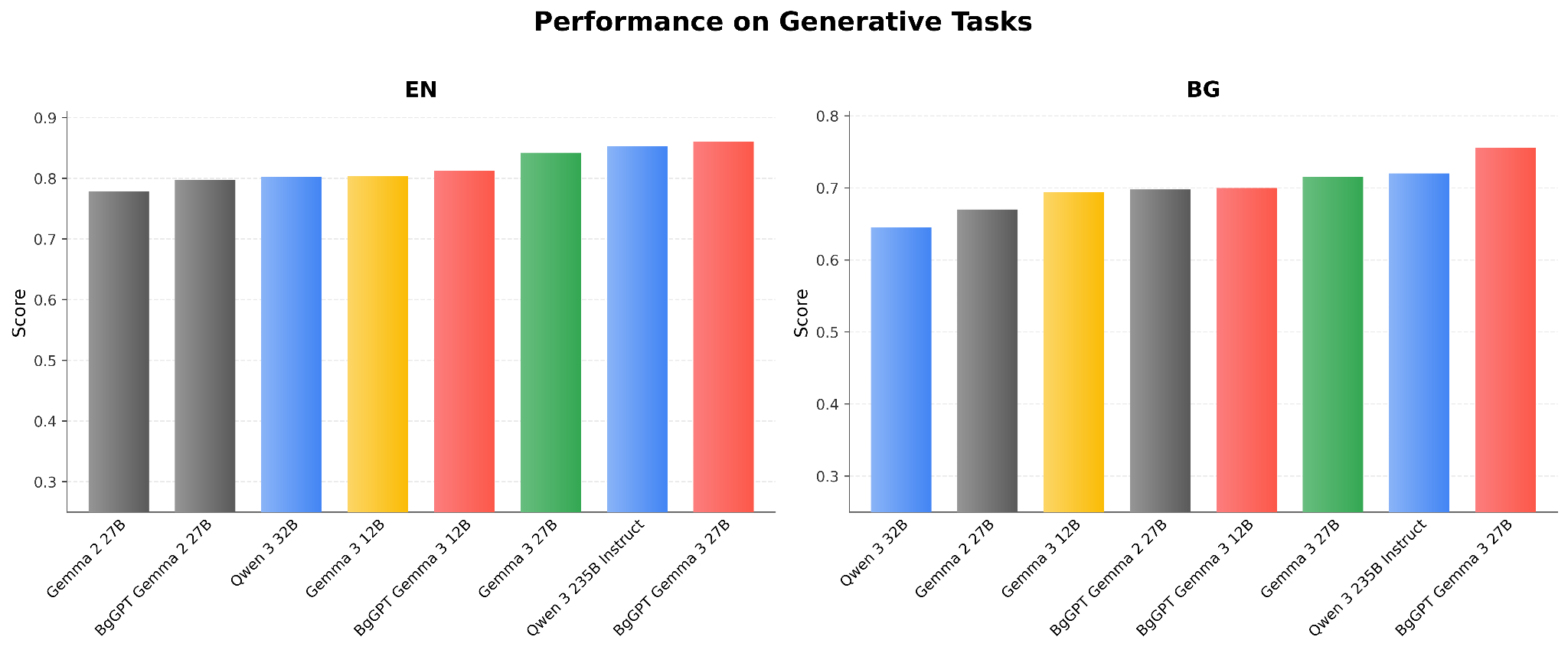
Evaluation Results of 9B and 27B Models on Benchmarks: Bulgarian and English


The results show the excellent abilities of both 9B and 27B models in Bulgarian, which allow them to outperform much larger models, including Alibaba’s Qwen 2.5 72B and Meta’s Llama3.1 70B. Further, both BgGPT 9B and BgGPT 27B significantly improve upon the previous version of BgGPT based on Mistral-7B (BgGPT-7B-Instruct-v0.2). Finally, our models retain the excellent English performance inherited from the original Google Gemma 2 models upon which they are based.
Benchmark Evaluation Results for the BgGPT-2.6B Model


In addition to BgGPT 9B and BgGPT 27B, INSAIT is also releasing BgGPT 2.6B, which is a state-of-the-art small language model for Bulgarian based on the Gemma-2 2.6B model. BgGPT 2.6B significantly improves over existing small language models such as Microsoft’s Phi 3.5 and Alibaba’s Qwen 2.5 3B. Again, as with the other BgGPT models, it retains the English capabilities of the underlying Gemma 2 2.6B model.
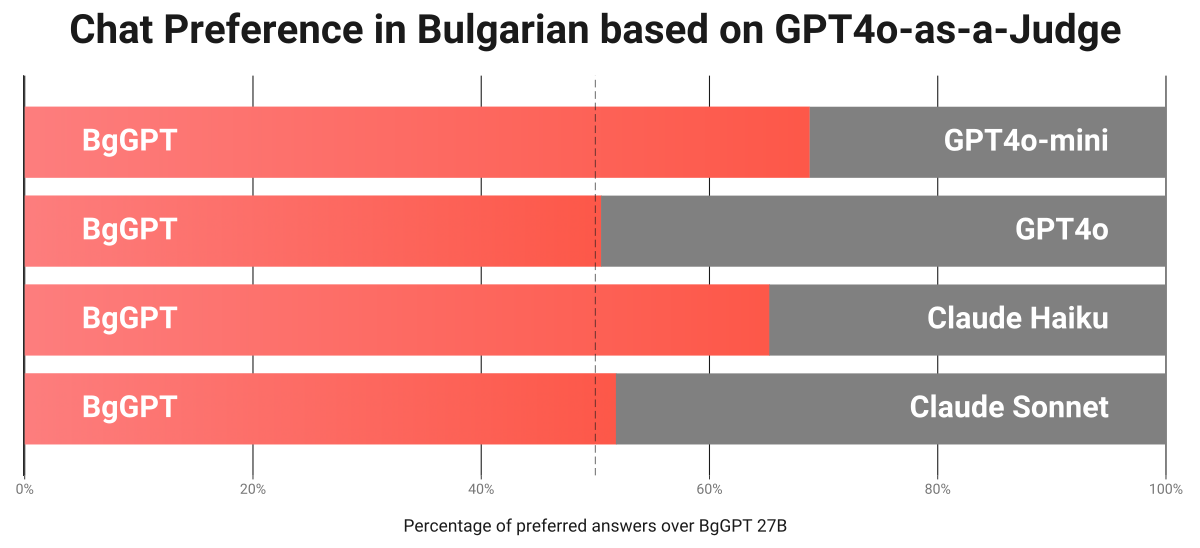
Chat Preference Evaluation of BgGPT 27B Model vs. OpenAI and Anthropic Models

In addition to benchmark evaluation, we evaluated the BgGPT 27B model in terms of chat performance on thousands of real-world questions from around 100 different topics. The results show that our model significantly surpasses the performance of the smaller variants of paid models, such as Anthropic’s Claude Haiku and OpenAI’s GPT-4o-mini in Bulgarian chat performance, and is on par with the best commercial models, such as Anthropic’s Claude Sonnet and OpenAI’s GPT-4o according to GPT-4o itself.
References
- Mitigating Catastrophic Forgetting in Language Transfer via Model Merging, Anton Alexandrov, Veselin Raychev, Mark Niklas Mueller, Ce Zhang, Martin Vechev, Kristina Toutanova. In Findings of the Association for Computational Linguistics: EMNLP 2024. https://aclanthology.org/2024.findings-emnlp.1000
- Winogrande: An adversarial winograd schema challenge at scale, Sakaguchi et al., 2021.
- Hellaswag: Can a machine really finish your sentence?, Zellers et al. arXiv:1905.07830
- Think you have solved question answering? Try ARC, the AI2 reasoning challenge, Clark et al. arXiv:1803.05457
- TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension, Joshi et al. arXiv:1705.03551
- Training verifiers to solve math word problems, Cobbe et al. arXiv:2110.14168
- EXAMS: A multi-subject high school examinations dataset, Hardalov et al. ACL 2020