· INSAIT · Release · 9 min read
BgGPT 3.0: Ново поколение мултимодални езикови модели за български
Пускаме BgGPT 3.0 — три нови отворени модела (4B, 12B, 27B), базирани на Gemma 3, с възможности за разбиране на визуално-езикови данни, 131k+ контекст и значително подобрено следване на инструкции за български и английски.
С удоволствие обявяваме пускането на BgGPT 3.0, нова серия LLM от най-висок клас с пермисивен лиценз, насочена към българския език. Пускаме три размера на моделите — 4B, 12B и 27B — които са рентабилни, бързи и мултимодални, но същевременно се представят конкурентно както на български, така и на английски. Моделите идват със силни базови и следващи инструкции възможности, надминаващи модели с отворени тегла с много по-големи размери.
В третата итерация на нашите адаптирани за български модели използваме Gemma 3 като здрава многоезична база за продължаващо предварително обучение и контролирано фино настройване. С по-силен базов модел и допълнителни корекции в обучителния процес, тази нова версия включва следните подобрения:
Разбиране на визуално-езикови данни: Моделите са проектирани да разбират както текст, така и изображения в един и същи контекст и ние се стремим да запазим и подобрим тази възможност, първоначално присъстваща в моделите Gemma 3.
Следване на инструкции: В тази итерация отделяме специално внимание на обучението на модела върху по-широк набор от задачи, многоходови разговори, по-сложни инструкции, както и системни подкани, което води до значително по-добро следване на инструкции и по-голяма полезност в сравнение с версия 2.0 на BgGPT.
По-дълъг контекст: С ефективен контекст от 131k токена, осигурен както от архитектурата и базовото обучение на моделното семейство Gemma 3, така и от внимателна адаптация от наша страна, BgGPT 3.0 вече поддържа по-дълги разговори, разбиране на дълги документи и може да следва по-дълги и по-сложни инструкции.
Актуализирана граница на знанията: В етапа на предварително обучение включваме допълнителни документи, извлечени от уеб, актуални към май 2025 г., докато етапът на фино настройване с инструкции съдържа знания до октомври 2025 г.
Подобрено продължително предварително обучение
Езиковият трансфер, подобно на други случаи на адаптация към домейн, поставя множество предизвикателства както от страна на данните, така и от страна на обучението в рамките на процеса, някои от които, като катастрофалното забравяне, адресирахме в предишни версии и изследвания — MamayLM, BgGPT, Alexandrov et al [1]. С по-силен мултимодален базов модел като Gemma 3, запазването на оригиналните възможности, т.е. смекчаването на катастрофалното забравяне, е по-важно от всякога. За да реализираме подобрения в различни модалности, езици и домейни, правим няколко ключови корекции на предишния ни процес (BgGPT 2.0).
Куриране на уеб данни
По-рано разчитахме на адаптиран RedPajama v2 процес [2], който ни помогна да съберем и курираме набор от уеб документи с дати на създаване не по-късни от октомври 2023 г. Този път правим няколко подобрения в следните аспекти:
Извличане. Актуализираме набора от налични документи чрез повторно парсване на по-старите и извличане на най-новите български от CommonCrawl, с крайна дата май 2025 г.
Дедупликация. Допълнително прилагаме последователно нашите нови точни и неточни процеси за дедупликация. От 113M уникални документа премахваме 78M чрез неточна дедупликация, оставяйки ни с предварителен набор от 35M документа.
Филтриране. Изследваме набор от метрики, базирани на статистика на документите, подобни на тези, използвани от RedPajama, RefinedWeb и други. Едно от по-значимите подобрения в тази област са наистина силните анотационни сигнали, които получаваме от JQL анотациите, базирани на Snowflake embeddings [3].
Рехидратация. След филтриране оставаме с ~23M документа, което съответства на по-малко от 40B токена. В предишни версии на BgGPT се целехме в 100B общо токена в набора от данни за продължително предварително обучение, но наблюдавахме, че количествено измеримите подобрения в бенчмарковете се забавят асимптотично. Вдъхновени от Muenninghoff et al., Fang et al. и FineWeb2 [4][5][6], извършваме стъпка на рехидратация, при която умишлено повтаряме документи въз основа на тяхното качество.
Конструиране на последователности
Съвременните LLM модели, като Gemma 3, обикновено преминават през финален етап на дълго-контекстно предварително обучение, при който се обучават специално с по-дълги последователности (напр. 32K токена за Gemma 3) и RoPE scaling. С тази цел, по време на етапа на продължаващо предварително обучение в нашия pipeline, ние внимателно конструираме нашите тренировъчни последователности, за да запазим възможностите за дълъг контекст, като същевременно намалим кръстосаната намеса между документи и катастрофалното забравяне. Прилагаме няколко техники за това, описани по-долу.
Клъстеризация на документи. Ние клъстеризираме документите въз основа на 320 центроида чрез техните Snowflake embeddings. Това ни позволява да конструираме мулти-документни последователности, които включват само документи от един и същи клъстер. Това намалява халюцинациите при реална употреба, като същевременно затваря домейн пропастта и подсилва дълго-контекстното обучение.
Best-fit Sequence Packing. Във всеки клъстер прилагаме силно ефективния Best-fit packing алгоритъм от Dint et al. [7], за да генерираме нашите токен последователности, като избягваме разделянето на документи, като същевременно добавяме по-малко от 1% padding токени.
Подравняване на модела
Най-ограниченият откъм данни етап в развитието на модела е контролираното инструкционно дообучение и подравняване. Има общ недостиг на български QA двойки, както и на български разговори и данни за предпочитания. За да адресираме тази празнина, използваме набор от техники за събиране на данни, включително превод, генериране на синтетични данни и човешка анотация. Накрая, сливането на моделите осигурява силна производителност на български бенчмаркове, подобрява подравняването и генерализацията и намалява катастрофалното забравяне.
Събиране на SFT данни
В предишни версии на BgGPT разчитахме основно на машинно преведени отворени набори от данни като Hermes, SlimOrca и Capybara. С увеличените възможности на SOTA моделите и широкото обществено приемане на предишни версии на BgGPT, нашият набор от данни се разшири, за да включи комбинация от синтетични, преведени и реални данни, което позволява на модела по-добри възможности за следване на инструкции.
За да улесним крослингвистичния трансфер, ние продължаваме да закотвяме нашето обучение към висококачествени преведени английски данни, съдържащи Math, Code и Function-calling примери, извлечени от източници като WildChat, Olmo-2 и Hermes 3. Освен това, ние използваме родни български данни за следване на инструкции, произхождащи от милионите заявки на потребители с изрично съгласие, събрани от нашето BgGPT чат приложение. Ние ги обработваме чрез строг филтриращ и синтетичен pipeline за генериране на данни, за да получим мащабен набор от данни от потребителски разговори, съдържащ разнообразен набор от теми, намерения на потребителите и качество на езика. Накрая, ние използваме instruction backtranslation [16], за да генерираме синтетични системни подкани за някои от тези разговори.
Branch-and-merge
Както и при нашите предишни BgGPT модели, ние използваме нашия ефективен метод за сливане на модели, представен в този Google DeepMind блог пост, за да подобрим подравняването на нашия модел. С тази цел използваме както силната базова, така и подравнената версия на Gemma 3, както и нашите собствени дообучени модели.
Преди сливането, нашите дообучени модели показват ограничени подобрения спрямо оригиналните Gemma 3 модели. Въпреки това, когато започнем да ги сливаме, виждаме, че получените модели се представят значително по-добре от отделните модели, които съставят сливането. Техниката за сливане, която открихме за най-стабилна и ефективна, е Spherical Linear Interpolation (SLERP).
Експериментални резултати
Разширяваме нашия оригинален набор от бенчмаркове, обсъден в BgGPT 1.0 [8], с IFEval [9], BBH (BigBenchHard) [10], LongBench [11], MMMU [12] и EXAMS-V [13], за да отговорим на нуждата от измерване на следване на инструкции, разсъждение, дълъг контекст и възможности за визуално-текстова обработка. IFEval и BBH изискваха значителни усилия отвъд машинния превод, за да бъдат адаптирани към български, докато използвахме Universal self-improvement [14], за да преведем LongBench. Можете да намерите българските адаптации на тези бенчмаркове на нашата HuggingFace организационна страница.
В нашите оценки, освен предишни версии на BgGPT, ние също сравняваме със семейството модели Gemma 3, тъй като те показват най-силните многоезични възможности както за техния размер, така и по-общо. Сравняваме BgGPT и със семейството модели Qwen, също създадени с мисъл за многоезичност, но с по-изразена ориентация към Източна Азия. Сравняваме с 2 модела от серията Qwen 3 [15], които са в подобен диапазон на скорост на извод, а именно 32B dense модел и 235B-Instruct MoE, като последният, разбира се, изисква няколко пъти повече памет за обслужване.
Генеративни задачи
С изключение на LongBench, нашият набор от генеративни бенчмаркове се състои от TriviaQA, GSM8k, IFEval и BigBenchHard. Фигура 1 представя агрегираните резултати от тези 4 бенчмарка за различните модели. Виждаме, че BgGPT Gemma 3 27B превъзхожда всички Gemma и двата Qwen 3 модела както на български, така и на английски. Важно е да се отбележи, че тази агрегация прикрива определени силни и слаби страни на моделите. Например, сравнявайки оригиналния Gemma 3 12B на Google с нашия предишен BgGPT Gemma 2 27B, въпреки техните сходни агрегирани български резултати, наблюдаваме 15% по-ниски резултати в TriviaQA, произтичащи от специфичните за българския език знания на предишния ни модел, но 9% по-високи резултати в IFEval, демонстриращи подобрените възможности за следване на инструкции на моделите Gemma от трето поколение. BgGPT Gemma 3 27B комбинира силните страни и на двата модела, постигайки 14% по-високи резултати на IFEval в сравнение с BgGPT Gemma 2 27B, като същевременно запазва предимствата на TriviaQA.
Фигура 1: Резултати на генеративни задачи
Задачи с дълъг контекст
Виждаме, че за оригиналния английски LongBench разликите в представянето между моделите са умерени, докато за български, в Фигура 2 е очевидна по-голяма вариация. Подобренията на BgGPT спрямо Gemma 3 моделите със същия размер са последователни и значими за българския език, а 27B BgGPT моделът също превъзхожда дори много по-големия Qwen 3 235B модел.
Фигура 2: Резултати на задачи с дълъг контекст
Задачи с изображения и текст
Във Фигура 3 наблюдаваме, че моделите BgGPT и на двата размера подобряват резултатите на английските (MMMU) и българските (EXAMS-V) бенчмаркове за визуално-текстова обработка в сравнение с немодифицираните Gemma 3 инструкционни модели. Тези подобрения в представянето се постигат безплатно: ние не извършваме мултимодално обучение, а само добавяме оригиналната визуална кула към адаптираните езикови модели. Резултатите са изненадващи, като се има предвид, че EXAMS-V е бенчмарк с избор от няколко отговора, който не съдържа текст в заявките, което може да оспори предположението, че подобрението произтича единствено от увеличените възможности за разбиране на езика.
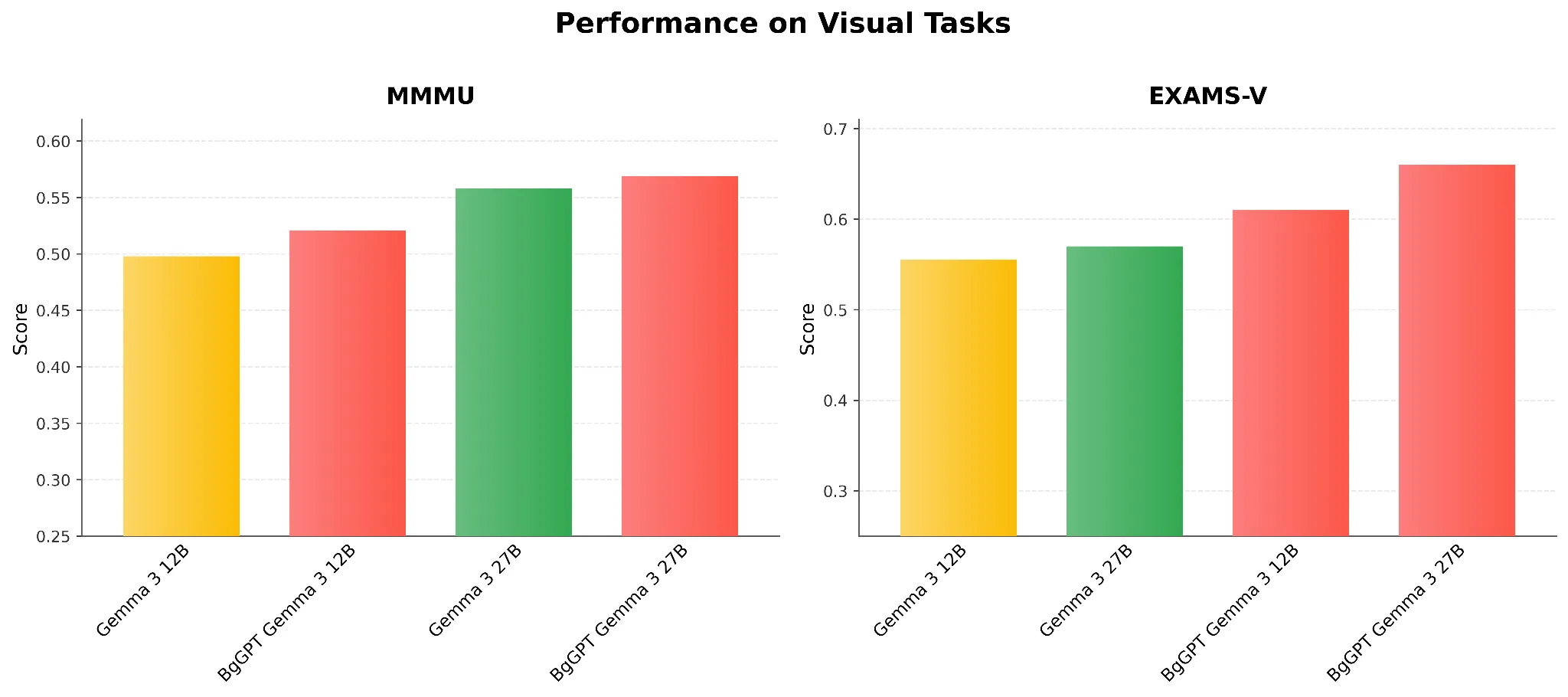
Фигура 3: Резултати на визуални задачи
Резултати на базовия модел
Накрая, демонстрираме възможностите на BgGPT Gemma 3 като базов модел, въпреки че е силно настроен за инструкции, с превъзходно представяне на бенчмаркове за лог-вероятност.
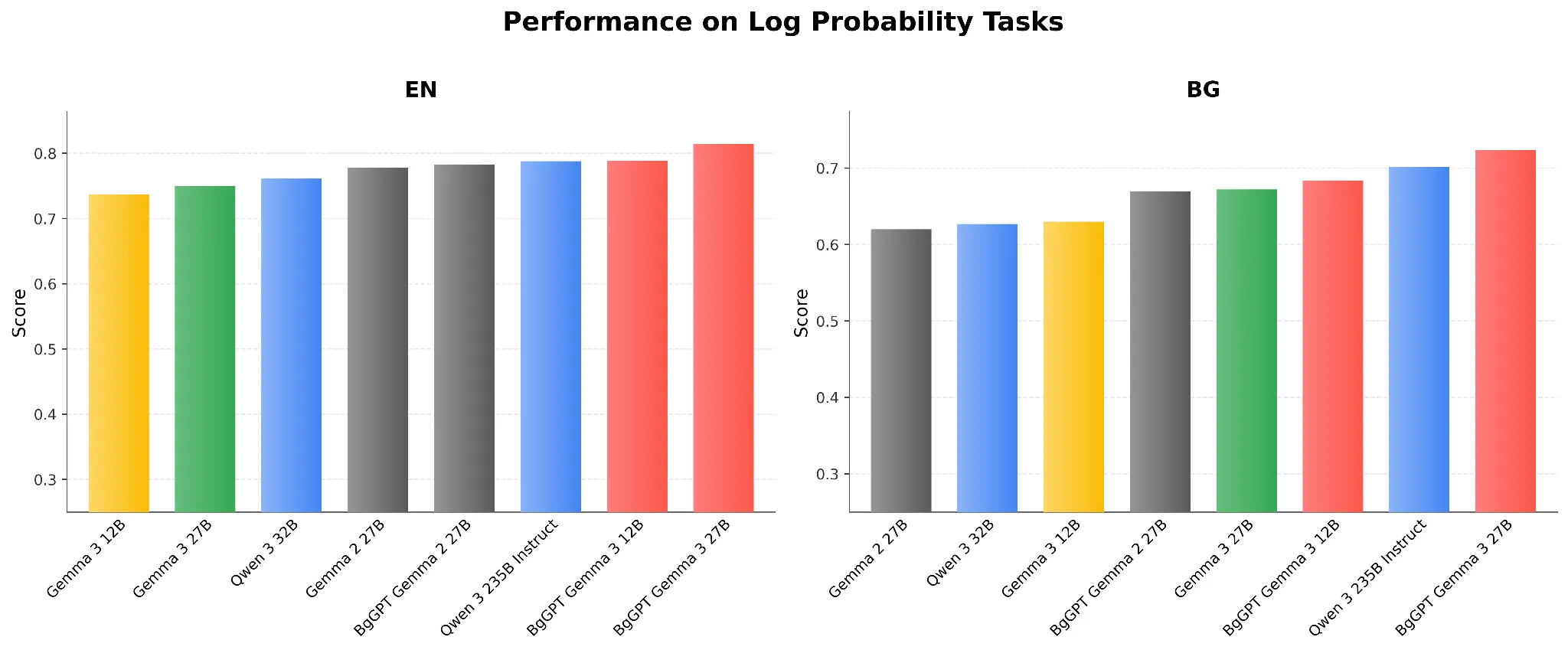
Фигура 4: Резултати на бенчмаркове за лог-вероятност
INSAIT благодари на Google за продължаващата подкрепа, както по отношение на GCP кредитите, необходими за обучението на моделите BgGPT, така и на даренията, необходими за работа отвъд обучението.
Препратки
- Mitigating Catastrophic Forgetting in Language Transfer via Model Merging. Findings of EMNLP, 2024. https://aclanthology.org/2024.findings-emnlp.1000/
- RedPajama: an Open Dataset for Training Large Language Models. NeurIPS Datasets & Benchmarks, 2024.
- Judging Quality Across Languages: A Multilingual Approach to Pretraining Data Filtering with Language Models. EMNLP, 2025. https://aclanthology.org/2025.emnlp-main.449
- Scaling Data-Constrained Language Models. arXiv, 2023. https://arxiv.org/abs/2305.16264
- Datasets, Documents, and Repetitions: The Practicalities of Unequal Data Quality. ACL, 2022. https://arxiv.org/abs/2107.06499
- FineWeb2: One Pipeline to Scale Them All — Adapting Pre-Training Data Processing to Every Language. arXiv, 2025. https://arxiv.org/abs/2506.20920
- Fewer Truncations Improve Language Modeling. ICML 2024. https://arxiv.org/abs/2404.10830
- BgGPT 1.0: Extending English-centric LLMs to other languages. arXiv, 2024. https://arxiv.org/abs/2412.10893
- Instruction-Following Evaluation for Large Language Models. ICLR, 2024. https://arxiv.org/abs/2311.07911
- Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them. Findings of ACL, 2022. https://aclanthology.org/2023.findings-acl.824
- LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. ACL, 2024. https://aclanthology.org/2024.acl-long.172/
- MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI. CVPR, 2024.
- EXAMS-V: A Multi-Discipline Multilingual Multimodal Exam Benchmark for Evaluating Vision Language Models. arXiv, 2024. https://arxiv.org/abs/2403.10378
- Recovered in Translation: Efficient Pipeline for Automated Translation of Benchmarks and Datasets. arXiv, 2026. https://arxiv.org/pdf/2602.22207
- Qwen3 Technical Report. arXiv, 2025. https://arxiv.org/abs/2505.09388
- Self-Alignment with Instruction Backtranslation. arXiv, 2023. https://arxiv.org/abs/2308.06259