· INSAIT · Release · 4 min read
INSAIT с нови езикови модели за български, установявайки нов стандарт за големи езикови модели на национално ниво
INSAIT пуска три нови BgGPT модела (27B, 9B, 2.6B) базирани на Gemma 2, надминаващи много по-големи отворени модели на български, конкурентни с GPT-4o при чат.
За пръв път отворени езикови модели с практичен размер за конкретен език надминават по ефективност много по-големи отворени модели, като същевременно са конкурентоспособни за чат с платени платформи като OpenAI и Anthropic.
INSAIT обявява пускането на три нови AI модела на световно ниво — 27 милиарден (BgGPT 27B), 9 милиарден (BgGPT 9B) и малък модел с 2.6 милиарда параметъра (BgGPT 2.6B), специално за български език. Моделите BgGPT 27B и 9B демонстрират безпрецедентни резултати върху български тестове, надминавайки много по-големи модели, като същевременно запазват способностите си на английски език. Отвъд резултатите на тестовете за български, допълнително тествахме и способностите на моделите за чат. Според самия GPT-4o, използван като съдия, BgGPT 27B значително надминава GPT-4o-mini и се конкурира с GPT-4o при чат на български. Наблюдаваме подобни резултати с платените модели на Anthropic — Claude Haiku и Claude Sonnet.
Моделите на INSAIT са базирани на семейството от отворени модели на Google — Gemma 2 и са обучени на около 100 милиарда токена (85 млрд. от тях на български). Обучението е извършено с помощта иновативен метод, основан на сливане на модели, който INSAIT изобрети, описа и представи на EMNLP’24 [1]. Допълнително моделите са специално настроени, използвайки български набор от данни с инструкции от чат приложението https://chat.bggpt.ai/.
Справяне с катастрофално забравяне чрез разклоняване и сливане

Ключът към ефективността на новите модели BgGPT е алгоритъмът за разклоняване и сливане, който беше представен на EMNLP’24 [1]. Този метод позволява на модела да научава нови умения (например български език), като същевременно запазва старите (например английски език, математика или “few-shot” способности), налични в основния модел (в случая Gemma-2).
В основни линии методът работи като разделя тренировъчните данни на няколко части и тренира отделни модели на всеки един от тях, които след това се сливат, за да се получи крайният модел. С помощта на този метод, до голяма степен се избягва катастрофалното забравяне, което обикновено се случва при обучението на само един модел.
Процесът на разработка на моделите BgGPT се състои от поредица от сливания на модели. Следва етап на обучение върху български набор от данни с инструкции от чат приложението. Отбелязваме, че методологията ни е общоприложима и може да бъде използвана както за български, така и за други езици, както и се описва в статията ни [1].
Тестове на български и английски език
Анализирахме способностите на моделите върху набор от стандартни тестове на английски, техни преводи на български, както и специфични тестове на български, които сме събрали:
- Winogrande предизвикателство [2]: тества общи познания и разбиране
- Hellaswag [3]: тества способността за довършване на изречения
- ARC Easy/Challenge [4]: тества логически разсъждения
- TriviaQA [5]: тества фактологични знания
- GSM-8K [6]: тества въпроси по математика на гимназиално ниво
- Exams [7]: тества решаване на задачи на гимназиално ниво за природни и социални науки
- MON: включва изпити по предмети от 4 до 12 клас
Този набор от данни тества логическото разсъждаване, цялостните математически познания, езиковото разбиране и други умения на моделите.
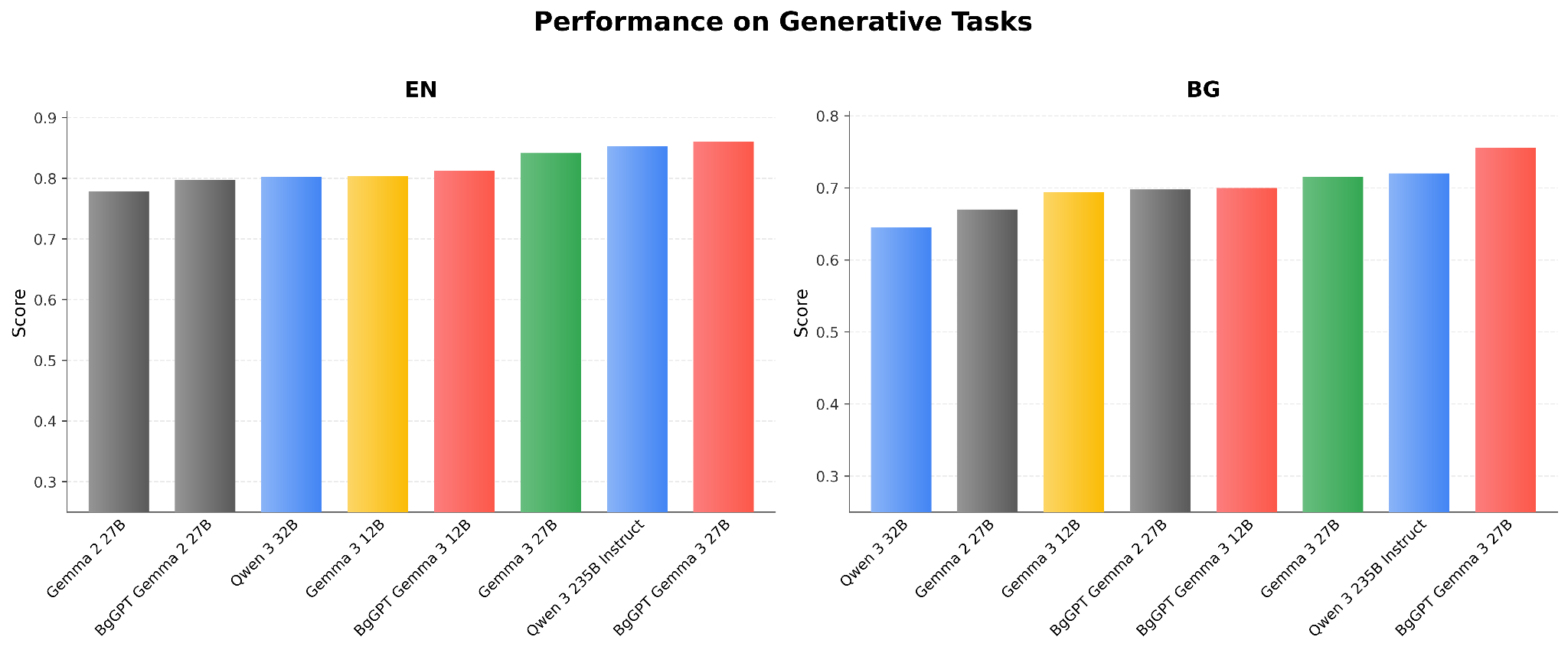
Резултати на BgGPT 9B и BgGPT 27B на български и английски език


Графиките показват резултатите на BgGPT 9B и BgGPT 27B в сравнение с други големи отворени модели. Резултатите на български сочат, че уменията и на двата модела превъзхождат тези на много по-големи такива като Qwen 2.5 72B на Alibaba и Llama3.1 70B на Meta. Също така BgGPT 9B и 27B значително надграждат над предишната версия на BgGPT — BgGPT-7B-Instruct-v0.2, базирана на Mistral-7B.
Резултати на BgGPT 2.6B на български и английски език


Освен BgGPT 9B и BgGPT 27B, INSAIT пуска и BgGPT 2.6B, малък езиков модел на български, базиран на Gemma-2 2.6B. На графиката показваме, че на нашия български набор от тестове, BgGPT 2.6B се справя значително по-добре от модели със същия размер като Phi 3.5 на Microsoft и Qwen 2.5 3B на Alibaba. Отново, както и с другите BgGPT модели, BgGPT 2.6B запазва способностите на Gemma 2 2.6B на английски език.
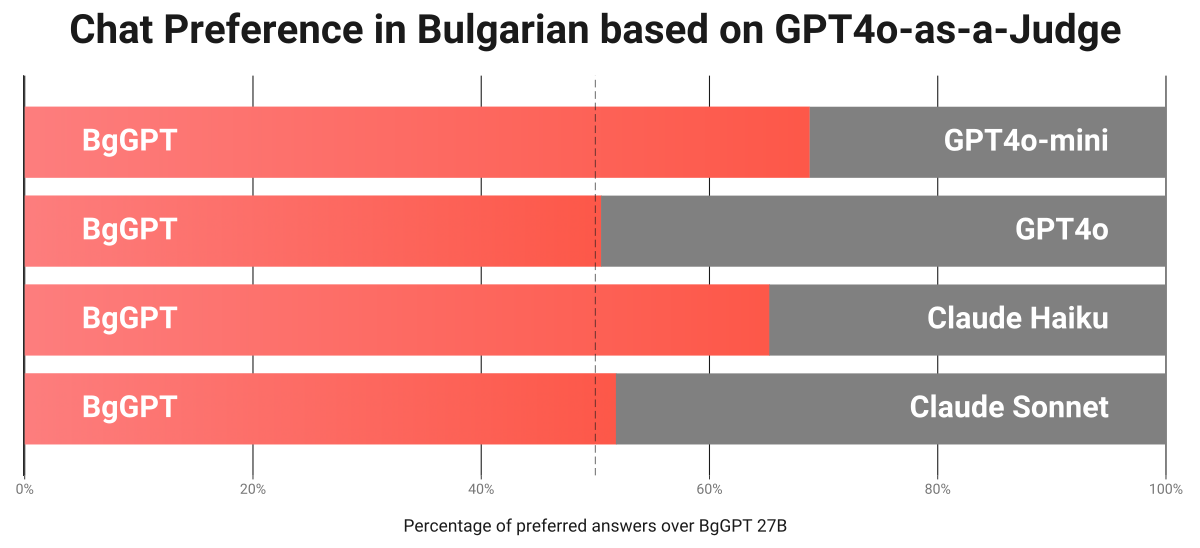
Чат предпочитания на български език спрямо комерсиалните модели на OpenAI и Anthropic

Освен българските тестове, проверихме качеството на BgGPT 27B и по отношение на отговори на чат въпроси на около 100 различни теми. Резултатите показват, че той значително надминава по-малките варианти на моделите на Anthropic (Claude Haiku) и OpenAI (GPT-4o-mini) при работа на български език, и е наравно с най-добрите комерсиални модели като Claude Sonnet и GPT-4o според самия GPT-4o.
Препратки
- Mitigating Catastrophic Forgetting in Language Transfer via Model Merging, Anton Alexandrov, Veselin Raychev, Mark Niklas Mueller, Ce Zhang, Martin Vechev, Kristina Toutanova. In Findings of the Association for Computational Linguistics: EMNLP 2024. https://aclanthology.org/2024.findings-emnlp.1000
- Winogrande: An adversarial winograd schema challenge at scale, Sakaguchi et al., 2021.
- Hellaswag: Can a machine really finish your sentence?, Zellers et al. arXiv:1905.07830
- Think you have solved question answering? Try ARC, the AI2 reasoning challenge, Clark et al. arXiv:1803.05457
- TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension, Joshi et al. arXiv:1705.03551
- Training verifiers to solve math word problems, Cobbe et al. arXiv:2110.14168
- EXAMS: A multi-subject high school examinations dataset, Hardalov et al. ACL 2020